

▣ 우선 cmd 명령 프롬프트를 실행하셔서
pip install requests beautifulsoup4를 설치해주세요.

▣ 먼저 우리가 www.naver.com 네이버를 들어가서 간단한 정보를 가지고 오겠습니다.
홈페이지에 들어가서 F12 키를 누르시면 개발자도구가 나오는 걸 확인할 수 있습니다.
웹사이트에 코드라고 생각하시면 되는데 html 형식으로 되어 있습니다.

▣ 먼저 import urllib.request 를 선언해주세요.
이건 쉽게 이야기해서 웹사이트에 정보를 요청해서 그 정보를 읽어오는 모듈이라고 생각하시면 됩니다.
그리고 url 변수에 = "http://www.navercom" 문자열 형식으로 대입을 해주세요.
req = urllib.request.urlopen(url) 을 넣어주세요. 이건 웹사이트에 연결을 요청하는 코드라고 생각하시면 됩니다.
req = urllib.request.urlopen("http://www.navercom") 이렇게 직접 매개변수에 홈페이지에 주소를 넣으셔도 무관합니다.
res = req.read() 로 연결된 웹사이트를 res에 정의해주세요.
그리고 print()함수로 출력을 해보면 웹사이트에 데이터가 들어가는 걸 확인할 수 있습니다.
▣ 이번에는 BeautifulSoup 라이브러리를 사용해보겠습니다.
이건 HTML과 XML파일에서 데이터를 읽어내고 탐색, 검색, 수정을 간편하게 해주는 라이브러리라고 생각하시면 됩니다.
from bs4 import BeautifulSoup을 선언해주시고
soup = BeautifulSoup(res, 'html.parser')로 res 아까 요청했던 웹사이트에 html에 값을 가져오고
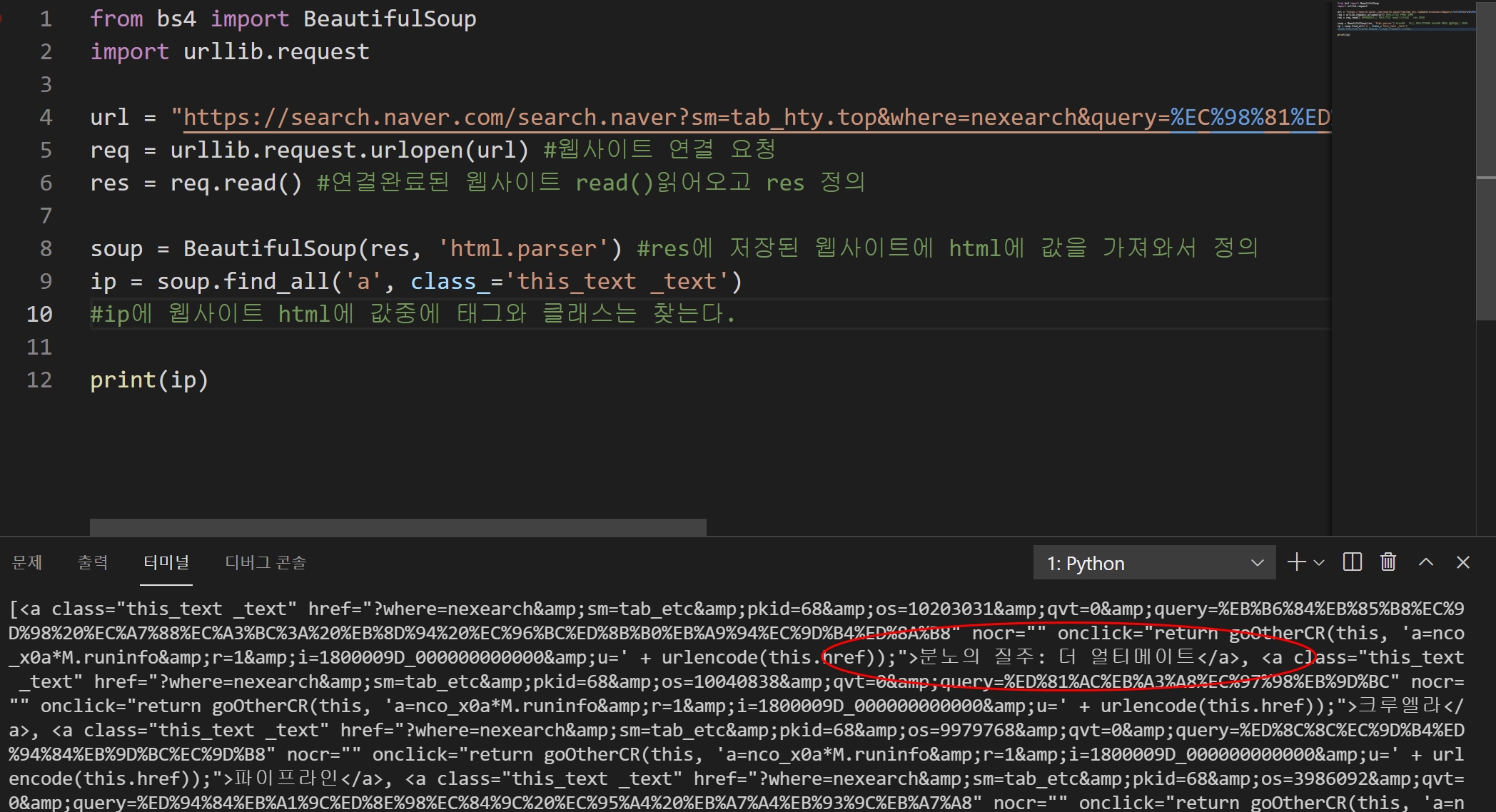
ip = soup.find_all('a', class_='this_text _text') ip에 soup html값에서 'a'라는 태그에 class_값을 가져와라라는 의미입니다.

▣ 이건 아까 네이버에서 영화라고 검색을 해주시고 F12를 눌러주시면 이렇게 창이 나오게 됩니다.

▣ 그럼 여기서 상단에 마우스포인터 모양을 누르고 내가 원하는 정보를 클릭하면 html 태그와 클래스가 있는 걸 볼 수 있습니다. 이 정보를 넣어주시면 됩니다.
그리고 출력을 해보면 그 태그와 클래스에 관련된 정보가 모두다 나오는 걸 확인할 수 있습니다.
그런데 이상한 코드까지도 함께 보이게 됩니다.
우리가 필요한건 영화에 이름 정보만 필요하기 때문에 코드를 넣어주겠습니다.
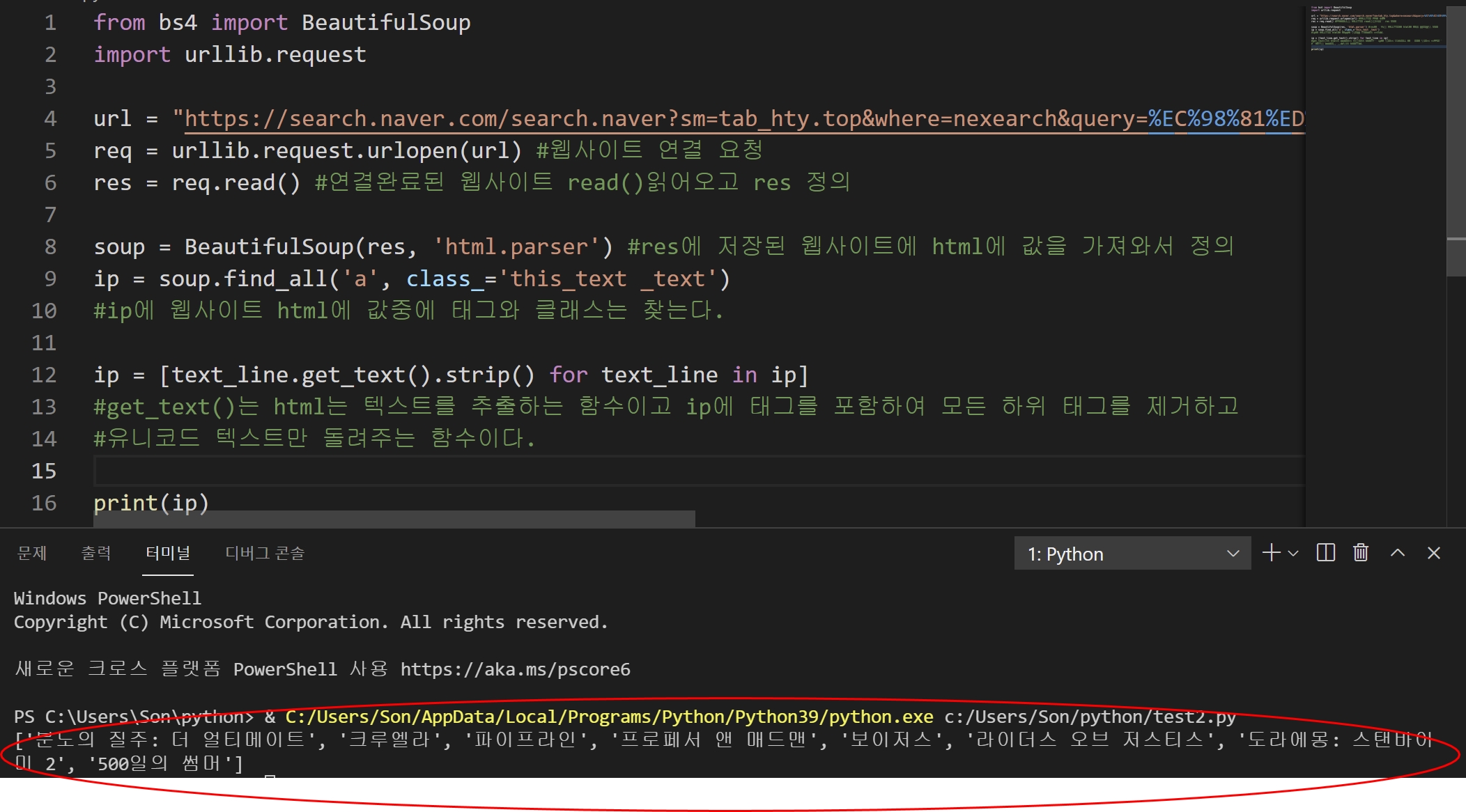
▣ 이렇게 ip = [text_line이라는 변수를 만들고, get_text() 함수를 사용합니다.
이 함수는 html에 있는 텍스트를 추출하는 함수인데 해상 웹사이트에 태그를 포함하여 모든 하위 태그를 제거하고
유니티 코드로 된 텍스트를 문자열로 돌려줍니다.
그리고 strip()함수로 공백을 제거해주는 코드입니다.
그런데 ip에 값을 하나하나 text_line에 넣어줘야 하기 때문에 이어서 for문을 사용했습니다.
for text_line in ip를 넣어서 ip에 값들을 하나하나 넣어서 ip에 넣어서 print함수로 출력을 하면
원하는 영화 이름만 출력되는걸 확인할 수 있습니다.
'[ Python ] > - 파이썬 실습연습' 카테고리의 다른 글
| pygame - [VS Code 자동완성] (2) | 2022.09.07 |
|---|---|
| python - [랜덤, Random] (2) | 2021.07.25 |
| 파이썬 - [pygame, 충돌감지_1, 스프라이트, collide] (2) | 2021.05.26 |
| 파이썬 - [이미지 애니메이션] (0) | 2021.05.20 |
| 파이썬 - [pygame, 마우스입력, 마우스좌표, event] (0) | 2021.05.15 |




댓글